[Python] 자율 주행을 시작하며(Sliding Window)
자율주행을 구상하며
자율주행에서 가장 중요한 점은 2가지, "속도"와 "정확도"라고 생각한다.
이 생각을 기반으로 자율주행에 접근했다.
이번 프로젝트는 콘을 인식하여 주행하는 것이 목표이다. 먼저, 자율주행에 대해 알아보기 위해 비슷한 차선 인식에 대해 알아보았다. 크게 2가지, 딥러닝 방식 또는 단순 알고리즘 방식이 존재했다. 이 중에서 속도가 더 빠르다고 생각이 든 단순 알고리즘 방식으로 접근했다.
- 목표 : 콘 인식 및 주행
- 개발환경 : Google 사의 Colab 및 IDLE
- 언어 : python
- 방식 : 단순 알고리즘
위와 같이 계획을 세우고 진행했다.
선행연구
위 논문은 자율주행을 프로그래밍하기 위해 찾아보던 논문 중 하나이다. 위 논문은 기존의 자율주행 알고리즘보다 논문에서 제시한 알고리즘이 더 빠르고, 정확성이 더 좋다는 사실을 주장했다. 따라서 이 논문이 제시하는 대로 코드를 작성해야겠다고 생각했다. 아래 그림은 논문에서 차선을 검출하기 위해 프로그래밍하는 순서도를 작성해놓은 것이다.
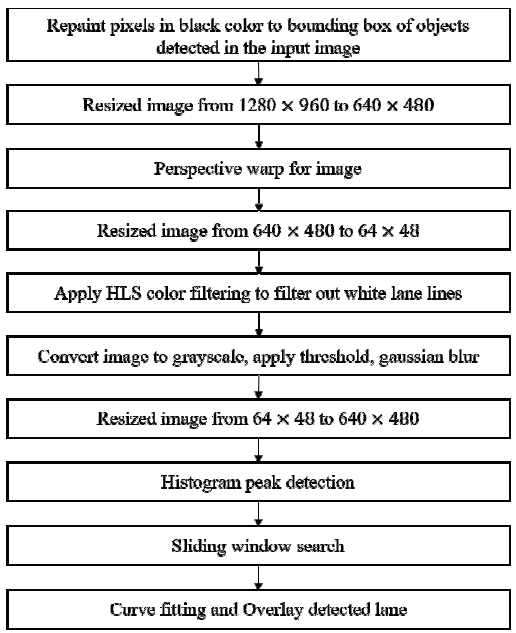
이는 차선 인식과 관련된 논문이었지만, 조금 변경한다면 콘 인식에도 적용할 수 있을 것이라 생각했다.
코드
이 순서도를 구현하기 위해 python의 OpenCV라는 모듈을 사용했다.
아래 코드의 순서는 위 순서도와 같다.
아래 #은 위 순서도를 번역한 것이다.
먼저 이 코드를 실행시키기 전에 cv2와 numpy에 관한 라이브러리를 설치한다.
#동영상을 640x480 크기로 변환한다.
#원근 뒤틀기(Perspective wrap)을 이용하여 차선을 일직선으로 편다.
#동영상을 64x48로 변환한다.
#흰색 차선을 검출하기 위해 HLS 필터링을 적용한다.
#동영상을 회색으로 변환하고, threshold와 가우스 블러를 적용한다.
#동영상을 640x480으로 변환한다.
#히스토그램을 사용하여 흰색 픽셀의 개수가 가장 많은 곳을 측정한다.
#흰색 픽셀의 개수에 따라 움직이는 window를 구현한다.
import cv2
import numpy as np
import matplotlib.pyplot as plt
minpix = 5
lane_bin_th = 145
path = "../source/2022-07-04_16-10-12.mp4" #동영상 주소
fps=30.
mp4_width=640
mp4_height=480
codec=cv2.VideoWriter_fourcc(*'DIVX')
path_birdView="../output/bird_view.mp4"
path_processing="../output/processing.mp4"
path_result="../output/result.mp4"
mp4_birdView=cv2.VideoWriter(path_birdView, codec, fps, (mp4_width, mp4_height))
mp4_processing=cv2.VideoWriter(path_processing, codec, fps, (mp4_width, mp4_height), False) #iscolor=False
mp4_result=cv2.VideoWriter(path_result, codec, fps, (mp4_width, mp4_height))
def warp_process_image(lane, current):
nwindows=10
margin = 50
global minpix
global lane_bin_th
leftx_current, rightx_current = current
window_height = 48
nz = lane.nonzero()
left_lane_inds = []
right_lane_inds = []
lx, ly, rx, ry = [], [], [], []
out_img = lane
out_img = np.dstack((lane, lane, lane))*255
for window in range(nwindows):
win_yl = lane.shape[0] - (window+1)*window_height
win_yh = lane.shape[0] - window*window_height
win_xll = leftx_current - margin
win_xlh = leftx_current + margin
win_xrl = rightx_current - margin
win_xrh = rightx_current + margin
cv2.rectangle(out_img,(win_xll,win_yl),(win_xlh,win_yh),(0,255,0), 2)
cv2.rectangle(out_img,(win_xrl,win_yl),(win_xrh,win_yh),(0,255,0), 2)
good_left_inds = ((nz[0] >= win_yl)&(nz[0] < win_yh)&(nz[1] >= win_xll)&(nz[1] < win_xlh)).nonzero()[0]
good_right_inds = ((nz[0] >= win_yl)&(nz[0] < win_yh)&(nz[1] >= win_xrl)&(nz[1] < win_xrh)).nonzero()[0]
left_lane_inds.append(good_left_inds)
right_lane_inds.append(good_right_inds)
if len(good_left_inds) > minpix:
leftx_current = np.int(np.mean(nz[1][good_left_inds]))
if len(good_right_inds) > minpix:
rightx_current = np.int(np.mean(nz[1][good_right_inds]))
lx.append(leftx_current)
ly.append((win_yl + win_yh)/2)
rx.append(rightx_current)
ry.append((win_yl + win_yh)/2)
left_lane_inds = np.concatenate(left_lane_inds)
right_lane_inds = np.concatenate(right_lane_inds)
#left_fit = np.polyfit(nz[0][left_lane_inds], nz[1][left_lane_inds], 2)
#right_fit = np.polyfit(nz[0][right_lane_inds] , nz[1][right_lane_inds], 2)
lfit = np.polyfit(np.array(ly),np.array(lx),2)
rfit = np.polyfit(np.array(ry),np.array(rx),2)
out_img[nz[0][left_lane_inds], nz[1][left_lane_inds]] = [255, 0, 0]
out_img[nz[0][right_lane_inds] , nz[1][right_lane_inds]] = [0, 0, 255]
#return left_fit, right_fit
return out_img, lfit, rfit
cap=cv2.VideoCapture(path)
while cap.isOpened(): # cap 정상동작 확인
ret, image = cap.read()
# 프레임이 올바르게 읽히면 ret은 True
if not ret:
print("프레임을 수신할 수 없습니다. 종료 중 ...")
break
image = cv2.resize(image, dsize=(640, 480))
#카메라 영상 촬영후 좌표조정하기
pts1 = np.float32([[250,240], [320,240], [50,350], [600,350]])
pts2 = np.float32([[0,0], [640,0], [0,480], [640,480]])
# 변환 행렬 계산
mtrx = cv2.getPerspectiveTransform(pts1, pts2)
# 원근 변환 적용
result = cv2.warpPerspective(image, mtrx, (640, 480))
smallimg=cv2.resize(result, dsize=(64, 48))
hsl=cv2.cvtColor(smallimg, cv2.COLOR_BGR2HLS)
imgH,imgS,imgL=cv2.split(hsl)
imgG=cv2.cvtColor(hsl, cv2.COLOR_BGR2GRAY)
#cv2.imshow('gray', imgG)
ret, thr=cv2.threshold(imgG, 127, 255, cv2.THRESH_OTSU)
blur = cv2.GaussianBlur(thr, (3,3),0)
imgBig=cv2.resize(blur, dsize=(640,480))
hist=imgBig.sum(axis=0)
plt.plot(hist)
current = np.argmax(hist[:320]), (np.argmax(hist[320:])+320)
#print(current)
out_img, lfit, rfit=warp_process_image(imgBig, current)
#cv2.imshow('origin', image)
cv2.imshow('bird_view', result)
cv2.imshow('processing', imgBig)
cv2.imshow('result', out_img)
mp4_birdView.write(result)
mp4_processing.write(imgBig)
mp4_result.write(out_img)
if cv2.waitKey(27) == ord('q'):
break
# 작업 완료 후 해제
cap.release()
mp4_birdView.release()
mp4_processing.release()
mp4_result.release()
cv2.destroyAllWindows()위 코드는 차선 인식을 구현하기 위한 코드이다. 위 코드로 테스트해본 결과 다음과 같이 나왔다.
결과
위 영상에서 알고리즘이 콘 인식 및 가상 차선 생성을 잘 하지 못한다.
따라서 콘을 인식하는 자율주행은 실패했다.
이번 결과는 콘을 차선을 인식할 때처럼 프로그래밍한다면 안된다는 점을 알려주었다. 차선은 이미지를 변환했을 때 사다리꼴에서 직사각형이 된 반면, 콘은 이미지를 변환했을 때 옆으로 늘어났다. 따라서 영상을 그대로 사용하면서 콘을 잇는 방법을 사용하려고 한다. 또한 다음 시도에서는 노이즈를 제거하고, 콘을 제외한 다른 사물이나 배경이 인식되지 않도록 조절하려고 한다.