성과물 :
먼저 OpenCV를 활용하여 만든 지금까지의 자율주행 성과물을 보여주겠다. 실로 대단하였다.

위의 이 영상은 자율주행을 시연하기 전 콘을 인식하여 가상의 차선을 그어본 것이다. 이것의 원리는 먼저 가상의 선을 미리 그어둔 후 거기에 가까운 점들을 추출하여 왼쪽 콘들, 오른쪽 콘들로 나눈다. 그 후, 이 콘들을 사용하여 다시 가상의 차선을 만들었다. 요약하자면 다음과 같다.
- 임의의 가상의 차선 긋기
- while(true):
- 가상의 차선을 바탕으로 콘 인식하기
- 콘들을 바탕으로 다시 가상의 차선 긋기(linear regression)
하지만 아직 많은 콘들을 뽑아내지 못한다는 단점이 있었다. 이러한 단점을 보완하기 위해 먼저 콘들을 추출하는 부분을 이미지화해보았다. 콘을 추출한 곳은 흰색 네모 박스가 쳐져 있다.
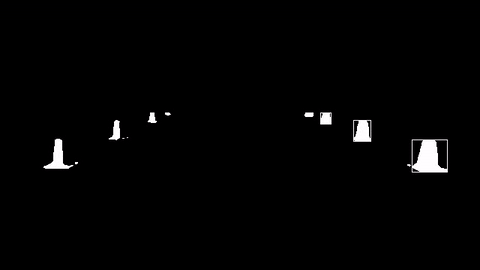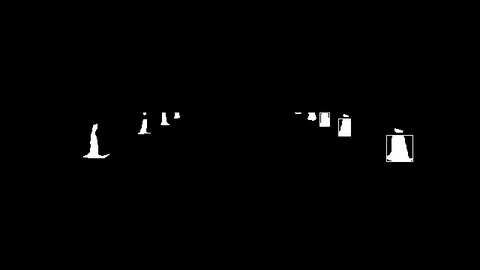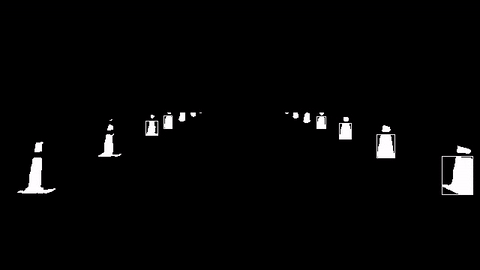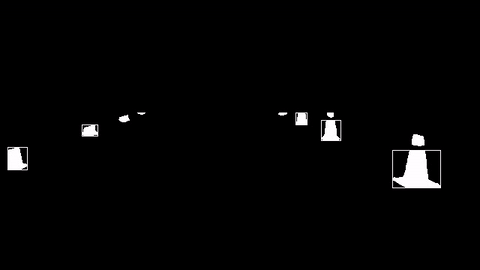
노란색은 콘 전체 부분이 인식되는 반면, 파란색은 인식이 거의 안됨을 볼 수 있다. 또한, 학교에서 테스트한 것과 달리 오른쪽, 왼쪽 콘 사이의 간격이 넓고 촘촘해서 기존의 ROI(관심 영역)를 수정해야 할 필요성을 느꼈다. 또한 주최 측에서 노란색, 파란색, 빨간색 콘의 위치를 고정할 것 같다고 말해서 기존의 알고리즘이 아니라 색상으로 콘을 분류하는 알고리즘을 만들어야 할 수도 있겠다. 다음은 이후 포스터의 방향이다.
- ROI 영역 넓히기
- HSV 색상 영역 조정하기
- 콘 분류 알고리즘의 정확도 개선
- 조향 알고리즘 개선
먼저 이전 포스팅을 본다면 threshold를 사용한 이유에 대해 알 수 있을 것이다.
[Python] OpenCV로 자율주행 만들기(Threshold)
이전 포스팅에서는 Canny threshold를 사용하였다. 하지만 이번에는 일반 Threshold를 사용하여 콘을 인식해 보았다. Canny threshold는 물체의 윤곽선을 따는 함수인데, 일반 Threshold는 물체의 윤곽선이 아
codezaram.tistory.com
그러면 코드에 대해 설명하겠다. 설명을 생략하고 싶다면 이 글의 제일 하단으로 가길 바란다.
CODE :
import matplotlib.pyplot as plt
import numpy as np
import cv2
import math
import time
path = "../source/WIN_20220925_14_36_35_Pro.mp4"
obj_b = cv2.imread('../source/corn_data/lavacorn_nb.png', cv2.IMREAD_GRAYSCALE)#wad
obj_s = cv2.imread('../source/corn_data/lavacorn_ns.png', cv2.IMREAD_GRAYSCALE)#wad
cap=cv2.VideoCapture(path) #path
obj_contours_b,_=cv2.findContours(obj_b, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE)#wad
obj_contours_s,_=cv2.findContours(obj_s, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE)#wad
obj_pts_b=obj_contours_b[0]#wad
obj_pts_s=obj_contours_s[0]#wad
fps = cap.get(cv2.CAP_PROP_FPS)
WIDTH = 640
HEIGHT = 360
rate=int(WIDTH/640)
codec = cv2.VideoWriter_fourcc(*'DIVX')
out=cv2.VideoWriter('../output/output_11_corn.mp4', codec, 30.0, (int(WIDTH),int(HEIGHT)), isColor=0)
kernel_size=5
low_threshold=30
high_threshold=255
theta=np.pi/180
threshold=90
p_r_m=0
p_r_n=0
p_l_m=0
p_l_n=0먼저 밑의 함수들을 활용하기 위해 모듈들을 import하고, 전역 변수를 설정해 주었다. 기능 중 궁금한 점이 있다면 댓글로 적어주길 바란다.
def grayscale(img):
hsv=cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
lower=(0, 150,80)
upper=(125, 255, 255)
mask_hsv=cv2.inRange(hsv, lower, upper)
img = cv2.bitwise_and(img, img, mask=mask_hsv)
img = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
return img그리고 저번 포스팅에서도 언급했듯이 rgb보다 hsv 색상이 콘의 색상을 따로 추출하는 것이 효과가 좋았다. 따라서 grayscale에 hsv영역으로 색을 바꾸어주는 함수를 써주었다.
def gaussian_blur(img, kernel_size):
return cv2.GaussianBlur(img, (kernel_size, kernel_size), 0)
def threshold(img, low_threshold, high_threshold):
"""Applies the Canny transform"""
return cv2.threshold(img, low_threshold, high_threshold, cv2.THRESH_BINARY)
def region_of_interest(img, vertices):
mask=np.zeros_like(img)
if len(img.shape)>2:
channel_count = img.shape[2]
ignore_mask_color=(255,)*channel_count
else:
ignore_mask_color=255
cv2.fillPoly(mask, vertices, ignore_mask_color)
masked_image=cv2.bitwise_and(img,mask)
return masked_image이후의 전처리 과정을 담당하는 함수들이다.
def depart_points(img, points, r_m, r_n, l_m, l_n):
r_list=[]
l_list=[]
for p in points:
if point2linear_distance(r_m, r_n, p) < point2linear_distance(l_m, l_n, p):
r_list.append(p)
else:
l_list.append(p)
return r_list, l_list
def gradient(p1, p2):
return (p2[1]-p1[1])/(p1[0]-p2[0])
def y_intercept(m, p):
return (-1)*p[1]-m*p[0]
def point2linear_distance(m,n,p):
return abs(m*p[0]-p[1]+n)/(m**2+1)**(1/2)
def linear_reg(img, left, right):
left_x=[]
left_y=[]
right_x=[]
right_y=[]
global p_r_m
global p_r_n
global p_l_m
global p_l_n
for i in range(len(left)):
left_x.append(left[i][0])
left_y.append(left[i][1])
for i in range(len(right)):
right_x.append(right[i][0])
right_y.append(right[i][1])
left_calculated_weight=0
right_calculated_weight=0
if len(left)<2:
left_calculated_weight=p_l_m
left_calculated_bias=p_l_n
else:
mean_lx=np.mean(left_x)
mean_ly=np.mean(left_y)
left_calculated_weight=least_square(left_x, left_y, mean_lx, mean_ly)
left_calculated_bias=mean_ly-left_calculated_weight*mean_lx
target_l=left_calculated_weight*WIDTH+left_calculated_bias
print(f"y = {left_calculated_weight} * X + {left_calculated_bias}")
if len(right)<2:
right_calculated_weight=p_r_m
right_calculated_bias=p_r_n
else:
mean_rx=np.mean(right_x)
mean_ry=np.mean(right_y)
right_calculated_weight=least_square(right_x, right_y, mean_rx, mean_ry)
right_calculated_bias=mean_ry-right_calculated_weight*mean_rx
target_r=right_calculated_weight*WIDTH+right_calculated_bias
print(f"y = {right_calculated_weight} * X + {right_calculated_bias}")
img = cv2.line(img,(int(WIDTH/2),HEIGHT),(int(WIDTH/2),int(0)),(255,0,0),3)
cross_x = (right_calculated_bias - left_calculated_bias) / (left_calculated_weight - right_calculated_weight)
cross_y = left_calculated_weight*((right_calculated_bias - left_calculated_bias)/(left_calculated_weight - right_calculated_weight)) + left_calculated_bias
if np.isnan(cross_x)!=True and np.isnan(cross_y)!=True:
img = cv2.line(img,(0,int(left_calculated_bias)),(int(WIDTH),int(target_l)),(0,0,0),10)
img = cv2.line(img,(int(0),int(right_calculated_bias)),(WIDTH,int(target_r)),(0,0,0),10)
cv2.circle(img, (int(cross_x), int(cross_y)), 10, (0, 0, 255), -1, cv2.LINE_AA)
if 80 < steering_theta(left_calculated_weight, right_calculated_weight) < 100:
print('소실점 조향 서보모터 각도: ', steering_vanishing_point(cross_x))
else:
print("기울기 조향 서보모터 각도: ", steering_theta(left_calculated_weight, right_calculated_weight))
p_l_m=left_calculated_weight
p_r_m=right_calculated_weight
p_l_n=left_calculated_bias
p_r_n=right_calculated_bias
#print('Done.')
return img
def least_square(val_x, val_y, mean_x, mean_y):
return ((val_x - mean_x) * (val_y - mean_y)).sum() / ((val_x - mean_x)**2).sum()다음은 추출한 콘들을 바탕으로 가상의 차선을 만드는 함수들이다.
def steering_theta(w1, w2):
if np.abs(w1) > np.abs(w2): # 우회전
if w1 * w2 < 0: #정방향 or 약간 틀어진 방향
w1 = -w1
angle = np.arctan(np.abs(math.tan(w1) - math.tan(w2)) / (1 + math.tan(w1)*math.tan(w2)))
theta = matching(angle, 0, np.pi/2, 90, 180)
elif w1 * w2 > 0: #극한으로 틀어진 방향
if w1 > w2:
theta = 90
else:
theta = 90
else:
theta = 0
elif np.abs(w1) < np.abs(w2) : # 좌회전
if w1 * w2 < 0: #정방향 or 약간 틀어진 방향
w1 = -w1
angle = np.arctan(np.abs(math.tan(w1) - math.tan(w2)) / (1 + math.tan(w1)*math.tan(w2)))
theta = matching(angle, 0, np.pi/2, 90, 0)
elif w1 * w2 > 0: #극한으로 틀어진 방향
if w1 > w2:
theta = 90
else:
theta = 90
else:
theta = 0
else:
theta = 90
return theta
def matching(x,input_min,input_max,output_min,output_max):
return (x-input_min)*(output_max-output_min)/(input_max-input_min)+output_min #map()함수 정의.
def steering_vanishing_point(x):
standard_x = int(WIDTH/2)
diff = standard_x - x
if diff > 0: #좌회전
theta = matching(diff, 0, WIDTH/2, 90, 45)
elif diff < 0:
theta = matching(diff, 0, -WIDTH/2, 90, 135)
return theta위의 코드는 조향 알고리즘이다.
while cap.isOpened():
ret, img = cap.read()
if not ret:
print("프레임을 수신할 수 없습니다. 종료 중 ...")
break
t=time.time()
img = cv2.resize(img, dsize=(int(WIDTH/rate), int(HEIGHT/rate)))
gray=grayscale(img)
blur_gray=gaussian_blur(gray, kernel_size)
if len(img.shape)>2:
channel_count=img.shape[2]
ignore_mask_color=(255,) * channel_count
else:
ignore_mask_color=255
mask=np.zeros_like(img)
vertices=np.array([[(10, 305),
(10, 200),
(180, 150),
(450, 150),
(630, 200),
(630, 305)]], dtype=np.int32)
cv2.fillPoly(mask, vertices, ignore_mask_color)
masked_image=region_of_interest(blur_gray, vertices)
ret2, edges=threshold(masked_image, low_threshold, high_threshold)
bigimg=edges
## 작업공간 ##
contours,_=cv2.findContours(bigimg, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE)
r_mid=[]
l_mid=[]
m_mid=[]
for pts in contours:
if cv2.contourArea(pts) <100:
continue
rc=cv2.boundingRect(pts)
dist_b=cv2.matchShapes(obj_pts_b, pts, cv2.CONTOURS_MATCH_I3, 0)
dist_s=cv2.matchShapes(obj_pts_s, pts, cv2.CONTOURS_MATCH_I3, 0)
if dist_b <0.4 or dist_s<0.2:
cv2.rectangle(bigimg, rc, (255, 0,0),1)
mid = [int((rc[0]*2+rc[2])/2), int((rc[1]*2+rc[3])/2)]
m_mid.append(mid)
## if mid[0]>WIDTH/2: #by vertices[2~3]/2 value
## r_mid.append(mid)
## else:
## l_mid.append(mid)
cv2.imshow("wjw", bigimg)
if p_r_m==0 and p_l_m==0:
p_r_m=0.3
p_r_n=37
p_l_m=-0.3
p_l_n=238
r_mid, l_mid = depart_points(img, m_mid, p_r_m,p_r_n,p_l_m,p_l_n)
for r in r_mid:
cv2.circle(img, r, 10, (0, 0, 255), -1, cv2.LINE_AA) #빨강
for l in l_mid:
cv2.circle(img, l, 10, (0, 255, 0), -1, cv2.LINE_AA) #초록
linear_img=linear_reg(img, l_mid, r_mid)
dt=time.time()-t
print("delay : ", dt)
cv2.imshow("ex", linear_img)#lines_edges
out.write(bigimg)
if cv2.waitKey(10) == ord('q'):
break
# 작업 완료 후 해제
cap.release()
out.release()
cv2.destroyAllWindows()위의 함수들을 모두 실행시켜 유의미한 결과를 만드는 것이다. while문을 이용하여 frame마다 계산하도록 만들었다.
전체 코드는 다음과 같다.
import matplotlib.pyplot as plt
import numpy as np
import cv2
import math
import time
path = "../source/WIN_20220925_14_36_35_Pro.mp4"
obj_b = cv2.imread('../source/corn_data/lavacorn_nb.png', cv2.IMREAD_GRAYSCALE)#wad
obj_s = cv2.imread('../source/corn_data/lavacorn_ns.png', cv2.IMREAD_GRAYSCALE)#wad
cap=cv2.VideoCapture(path) #path
obj_contours_b,_=cv2.findContours(obj_b, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE)#wad
obj_contours_s,_=cv2.findContours(obj_s, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE)#wad
obj_pts_b=obj_contours_b[0]#wad
obj_pts_s=obj_contours_s[0]#wad
fps = cap.get(cv2.CAP_PROP_FPS)
WIDTH = 640
HEIGHT = 360
rate=int(WIDTH/640)
codec = cv2.VideoWriter_fourcc(*'DIVX')
out=cv2.VideoWriter('../output/output_11_corn.mp4', codec, 30.0, (int(WIDTH),int(HEIGHT)), isColor=0)
kernel_size=5
low_threshold=30
high_threshold=255
theta=np.pi/180
threshold=90
p_r_m=0
p_r_n=0
p_l_m=0
p_l_n=0
def grayscale(img):
hsv=cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
lower_red=(0, 150,80)
upper_red=(125, 255, 255)
mask_hsv=cv2.inRange(hsv, lower_red, upper_red)
img = cv2.bitwise_and(img, img, mask=mask_hsv)
img = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
return img
def gaussian_blur(img, kernel_size):
return cv2.GaussianBlur(img, (kernel_size, kernel_size), 0)
def threshold(img, low_threshold, high_threshold):
"""Applies the Canny transform"""
return cv2.threshold(img, low_threshold, high_threshold, cv2.THRESH_BINARY)
def region_of_interest(img, vertices):
mask=np.zeros_like(img)
if len(img.shape)>2:
channel_count = img.shape[2]
ignore_mask_color=(255,)*channel_count
else:
ignore_mask_color=255
cv2.fillPoly(mask, vertices, ignore_mask_color)
masked_image=cv2.bitwise_and(img,mask)
return masked_image
def depart_points(img, points, r_m, r_n, l_m, l_n):
r_list=[]
l_list=[]
for p in points:
if point2linear_distance(r_m, r_n, p) < point2linear_distance(l_m, l_n, p):
r_list.append(p)
else:
l_list.append(p)
return r_list, l_list
def gradient(p1, p2):
return (p2[1]-p1[1])/(p1[0]-p2[0])
def y_intercept(m, p):
return (-1)*p[1]-m*p[0]
def point2linear_distance(m,n,p):
return abs(m*p[0]-p[1]+n)/(m**2+1)**(1/2)
def linear_reg(img, left, right):
left_x=[]
left_y=[]
right_x=[]
right_y=[]
global p_r_m
global p_r_n
global p_l_m
global p_l_n
for i in range(len(left)):
left_x.append(left[i][0])
left_y.append(left[i][1])
for i in range(len(right)):
right_x.append(right[i][0])
right_y.append(right[i][1])
left_calculated_weight=0
right_calculated_weight=0
if len(left)<2:
left_calculated_weight=p_l_m
left_calculated_bias=p_l_n
else:
mean_lx=np.mean(left_x)
mean_ly=np.mean(left_y)
left_calculated_weight=least_square(left_x, left_y, mean_lx, mean_ly)
left_calculated_bias=mean_ly-left_calculated_weight*mean_lx
target_l=left_calculated_weight*WIDTH+left_calculated_bias
print(f"y = {left_calculated_weight} * X + {left_calculated_bias}")
if len(right)<2:
right_calculated_weight=p_r_m
right_calculated_bias=p_r_n
else:
mean_rx=np.mean(right_x)
mean_ry=np.mean(right_y)
right_calculated_weight=least_square(right_x, right_y, mean_rx, mean_ry)
right_calculated_bias=mean_ry-right_calculated_weight*mean_rx
target_r=right_calculated_weight*WIDTH+right_calculated_bias
print(f"y = {right_calculated_weight} * X + {right_calculated_bias}")
img = cv2.line(img,(int(WIDTH/2),HEIGHT),(int(WIDTH/2),int(0)),(255,0,0),3)
cross_x = (right_calculated_bias - left_calculated_bias) / (left_calculated_weight - right_calculated_weight)
cross_y = left_calculated_weight*((right_calculated_bias - left_calculated_bias)/(left_calculated_weight - right_calculated_weight)) + left_calculated_bias
if np.isnan(cross_x)!=True and np.isnan(cross_y)!=True:
img = cv2.line(img,(0,int(left_calculated_bias)),(int(WIDTH),int(target_l)),(0,0,0),10)
img = cv2.line(img,(int(0),int(right_calculated_bias)),(WIDTH,int(target_r)),(0,0,0),10)
cv2.circle(img, (int(cross_x), int(cross_y)), 10, (0, 0, 255), -1, cv2.LINE_AA)
if 80 < steering_theta(left_calculated_weight, right_calculated_weight) < 100:
print('소실점 조향 서보모터 각도: ', steering_vanishing_point(cross_x))
else:
print("기울기 조향 서보모터 각도: ", steering_theta(left_calculated_weight, right_calculated_weight))
p_l_m=left_calculated_weight
p_r_m=right_calculated_weight
p_l_n=left_calculated_bias
p_r_n=right_calculated_bias
#print('Done.')
return img
def least_square(val_x, val_y, mean_x, mean_y):
return ((val_x - mean_x) * (val_y - mean_y)).sum() / ((val_x - mean_x)**2).sum()
def steering_theta(w1, w2):
if np.abs(w1) > np.abs(w2): # 우회전
if w1 * w2 < 0: #정방향 or 약간 틀어진 방향
w1 = -w1
angle = np.arctan(np.abs(math.tan(w1) - math.tan(w2)) / (1 + math.tan(w1)*math.tan(w2)))
theta = matching(angle, 0, np.pi/2, 90, 180)
elif w1 * w2 > 0: #극한으로 틀어진 방향
if w1 > w2:
theta = 90
else:
theta = 90
else:
theta = 0
elif np.abs(w1) < np.abs(w2) : # 좌회전
if w1 * w2 < 0: #정방향 or 약간 틀어진 방향
w1 = -w1
angle = np.arctan(np.abs(math.tan(w1) - math.tan(w2)) / (1 + math.tan(w1)*math.tan(w2)))
theta = matching(angle, 0, np.pi/2, 90, 0)
elif w1 * w2 > 0: #극한으로 틀어진 방향
if w1 > w2:
theta = 90
else:
theta = 90
else:
theta = 0
else:
theta = 90
return theta
def matching(x,input_min,input_max,output_min,output_max):
return (x-input_min)*(output_max-output_min)/(input_max-input_min)+output_min #map()함수 정의.
def steering_vanishing_point(x):
standard_x = int(WIDTH/2)
diff = standard_x - x
if diff > 0: #좌회전
theta = matching(diff, 0, WIDTH/2, 90, 45)
elif diff < 0:
theta = matching(diff, 0, -WIDTH/2, 90, 135)
return theta
while cap.isOpened():
ret, img = cap.read()
if not ret:
print("프레임을 수신할 수 없습니다. 종료 중 ...")
break
t=time.time()
img = cv2.resize(img, dsize=(int(WIDTH/rate), int(HEIGHT/rate)))
gray=grayscale(img)
blur_gray=gaussian_blur(gray, kernel_size)
if len(img.shape)>2:
channel_count=img.shape[2]
ignore_mask_color=(255,) * channel_count
else:
ignore_mask_color=255
mask=np.zeros_like(img)
vertices=np.array([[(10, 305),
(10, 200),
(180, 150),
(450, 150),
(630, 200),
(630, 305)]], dtype=np.int32)
cv2.fillPoly(mask, vertices, ignore_mask_color)
masked_image=region_of_interest(blur_gray, vertices)
ret2, edges=threshold(masked_image, low_threshold, high_threshold)
bigimg=edges
## 작업공간 ##
contours,_=cv2.findContours(bigimg, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE)
r_mid=[]
l_mid=[]
m_mid=[]
for pts in contours:
if cv2.contourArea(pts) <100:
continue
rc=cv2.boundingRect(pts)
dist_b=cv2.matchShapes(obj_pts_b, pts, cv2.CONTOURS_MATCH_I3, 0)
dist_s=cv2.matchShapes(obj_pts_s, pts, cv2.CONTOURS_MATCH_I3, 0)
if dist_b <0.4 or dist_s<0.2:
cv2.rectangle(bigimg, rc, (255, 0,0),1)
mid = [int((rc[0]*2+rc[2])/2), int((rc[1]*2+rc[3])/2)]
m_mid.append(mid)
## if mid[0]>WIDTH/2: #by vertices[2~3]/2 value
## r_mid.append(mid)
## else:
## l_mid.append(mid)
cv2.imshow("wjw", bigimg)
if p_r_m==0 and p_l_m==0:
p_r_m=0.3
p_r_n=37
p_l_m=-0.3
p_l_n=238
r_mid, l_mid = depart_points(img, m_mid, p_r_m,p_r_n,p_l_m,p_l_n)
for r in r_mid:
cv2.circle(img, r, 10, (0, 0, 255), -1, cv2.LINE_AA) #빨강
for l in l_mid:
cv2.circle(img, l, 10, (0, 255, 0), -1, cv2.LINE_AA) #초록
linear_img=linear_reg(img, l_mid, r_mid)
dt=time.time()-t
print("delay : ", dt)
cv2.imshow("ex", linear_img)#lines_edges
out.write(bigimg)
if cv2.waitKey(10) == ord('q'):
break
# 작업 완료 후 해제
cap.release()
out.release()
cv2.destroyAllWindows()



